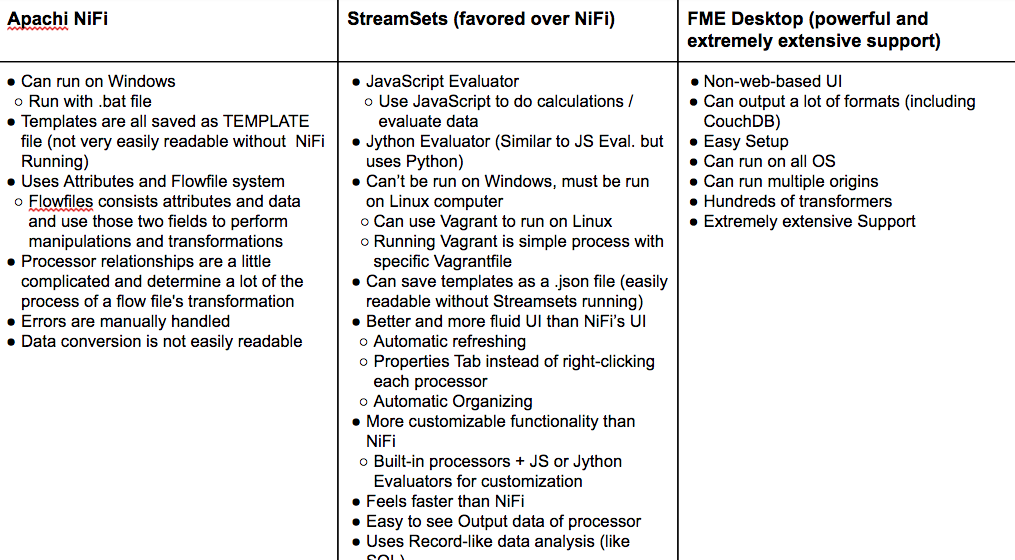
Structure
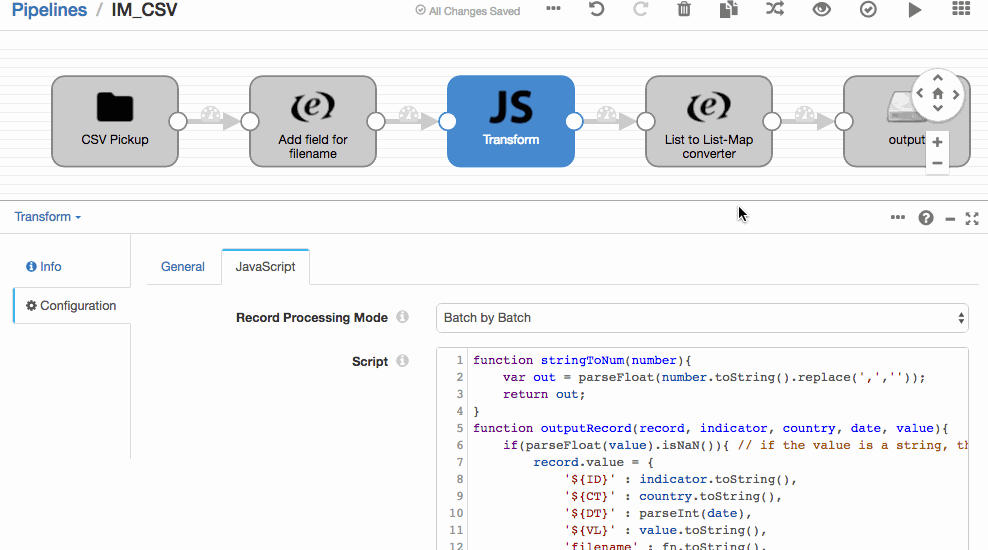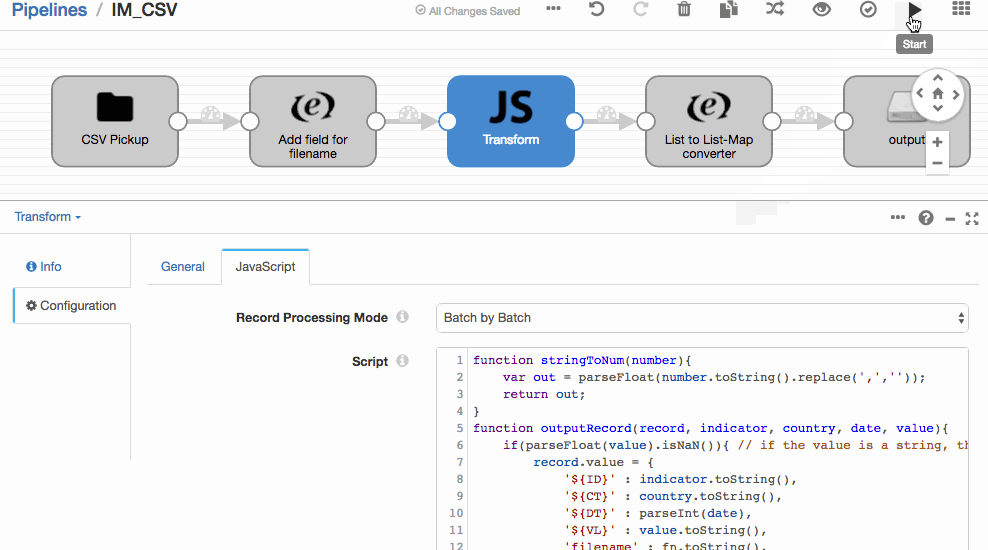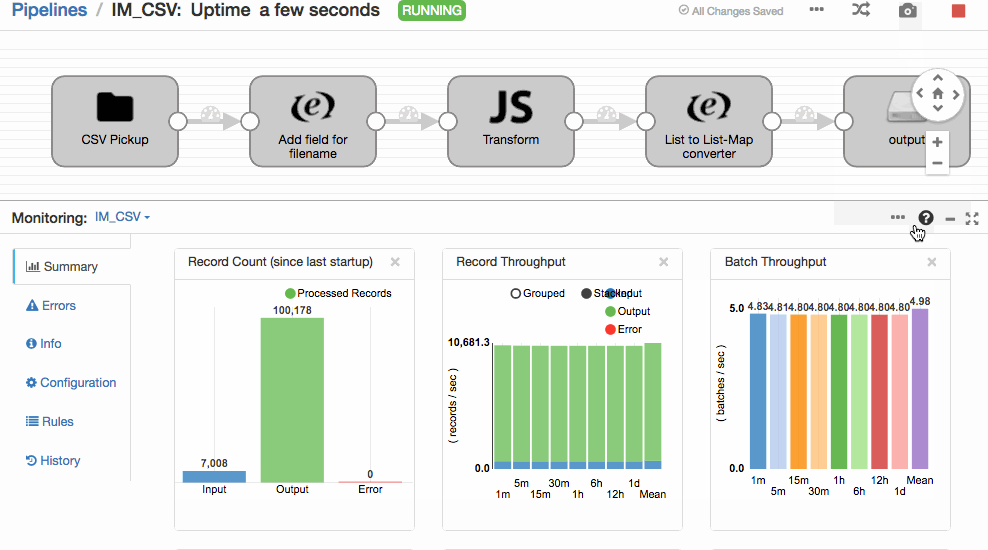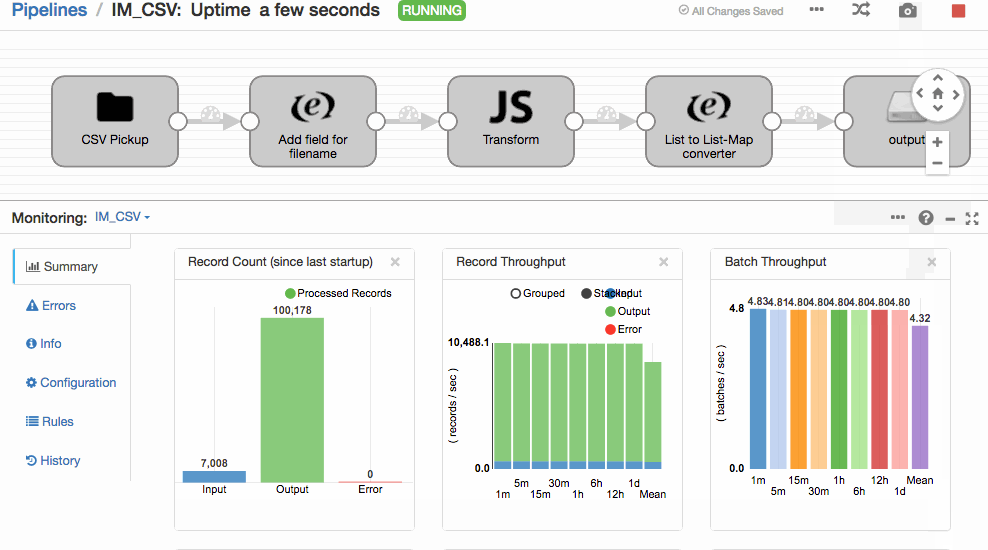
After deciding a platform, the next step was to develop a system that would help achieve our goal of running a scalable, modular, and reliable ETL process on demand. The system boiled down to one script.js file that runs all the logic and transformation of each file while Streamsets handled the input and output.
AddingNewDataSource.md explains the structure of all the code that performs the transformation in detail.
Quick Summary
There are three blocks of the code that are important to understand
- "outputRecord" function | Line #5
This function contains the syntax for outputting a record (one line in the csv file). It is executed at the end of each indicator function.
- All the indicator functions | Starts at line #25
Every indicator function contains the process to transform the origin file to the correct format. Though each function is unique, every function contains a similar structure outlined in AddingNewDataSource.md.
- Logic for which function to execute | Starts at line #536
This block contains the basic logic for which indicator function to execute using hard-coded Regex or filenames and a switch statement.