Motivation
During the winter break of 2017, I decided to work on a project that would make me learning something new. Inspired by this article, I decided to make my own trivia solver based on the trending HQTrivia app. In the following section, I am going to outline the approach that I designed and implemented.
High-level approach
If you have not played HQTrivia, the idea is to answer a multiple choice trivia question in under 10 seconds. If you can answer 12 questions in a row, you win a cash prize!
getting the data
The first thing that I needed to do was to find out how to grab the HQTrivia data. A lot of people used OCR along with hooking up their phone to their computer. But I figured there had to be a better way. After some research, I found someone who had sniffed the packets coming from their phone while the HQTrivia app was open and found out that HQTrivia serves their questions through a websocket connection (I had to learn how to use websockets). After doing the same thing, I was able to discover the schema and HQTrivia’s schema for questions. To do the packet sniffing, I used a web debugging proxy called Charles and proxied my phone’s network through my computer.
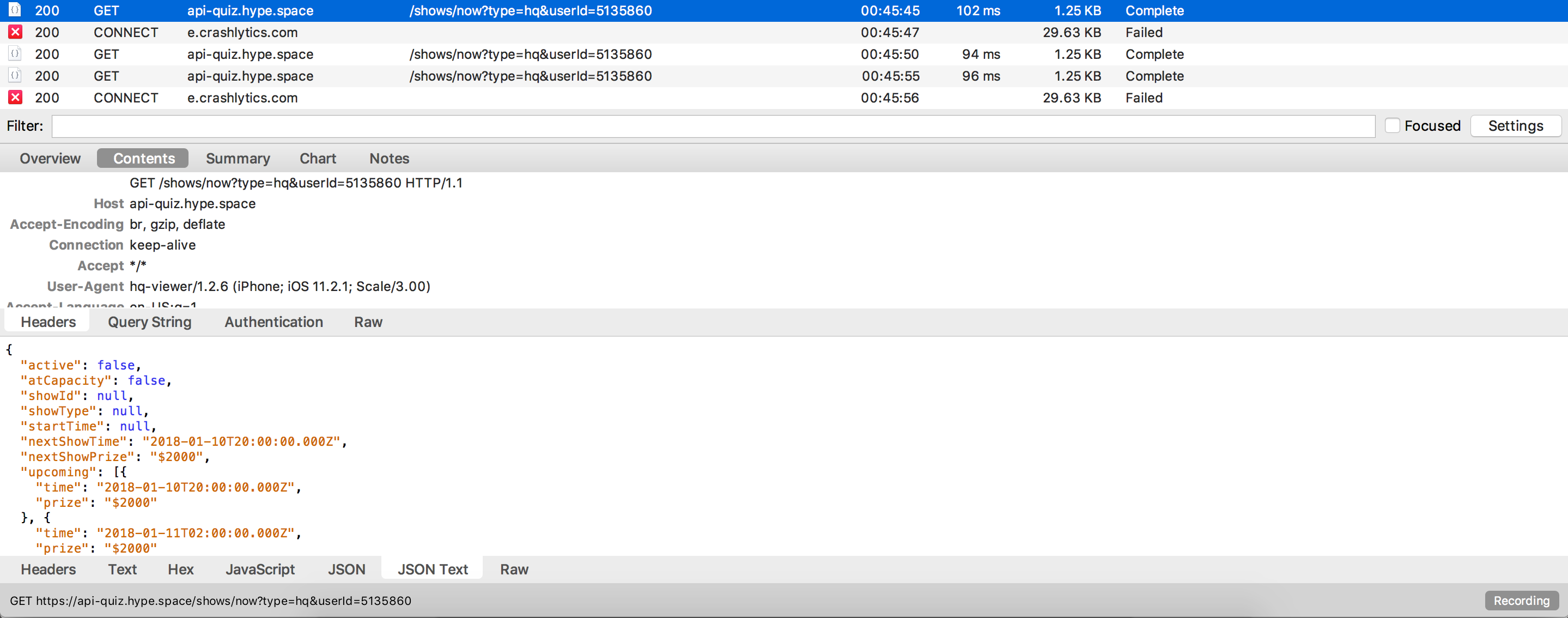
choosing the model
The next thing I knew was that I wanted to use some sort of machine learning model to solve the questions (lol buzz words), but I had no previous experience using a model to solve anything. The first thing I did was learn about what exactly a “model” is, what models currently exist, and what the hell a feature is.
After learning about my options for a model, I decided on using a decision tree with gradient boosting from the LightGBM by Microsoft because it was proven to be better than xgboost, but xgboost has proven to be extremely effective in machine learning competitions that require quick learning, classification, or learning on small amounts of data (due to gradient boosting).
creating the features
The next step was for me to create features. Below is a list of features that I designed using Google and Bing searches:
- Google search each answer and count number of occurrences for each evaluated important word
- Bing search each answer and count number of occurrences for each evaluated important word
- Google question and each answer, create document corpus from each answer search, compare cosine similarity of question search to corpus
- Google search each important word and count number of occurrences for each answer
- Bing search each important word and count number of occurrences for each answer
- Google question with each answer appended and count number of search results
- Google question with each answer appended and count number of search results
- Google important words with each answer appended and count number of search results
- Google noun chunks with each answer appended and count number of search results
- Wikipedia search each answer and count number of occurrences for each evaluated important word
- Google question with each answer appended in quotes and count occurrences of each answer
- Bing search question with each answer appended in quotes and count occurrences of each answer
- Google question with each answer appended in quotes and count occurrences of each important word
- Google evaluated noun chunks of question and count occurrences of each answer
- Google the question and count occurrences of each answer
Annoying thing
Since google rate limits your searches, I had to use a VPN to change every 3 questions during a game because I was doing upwards of 40 google searches for each question, depending on the evaluation of the question. Also, since network requests are relatively slow to CPU computation, I had to implement an immense amount of multithreading to deal with the massive amount of network I/O that I was executing for each question.
What I learned
- Gradient Boosting and LightGBM
- NLP with spaCy
- Machine Learning Features
- Websockets
- TF-IDF / Cosine Similarity
- Multithreading network requests
- Lots of Python
Conclusion
After months of testing and gathering data to train my supervised model, I was able to get about a ~80% accuracy rate (which is not that great if you think about the chance of getting 12 right in a row .8 ^ 12 = .0687) and at an average time of ~7 seconds per questions. I gathered a total of 629 questions. And I also won a game worth $53.19 dollars (note that its not my name because it was 3 of us and we decided to split on the last question to guarantee a win)!

All the gathered questions, model, and source code can be found here :)!